It Works! … With a 50% Error Rate
Saturday Dinner Time. 18 hours until presentation (or T-minus 10 hours if you minus our sleep, etc) We pushed forward and I started fine-tuning the language model. As the Loss function of our model “converged” – (fancy jargon meaning it started figuring things out) – I was euphoric!
The Eureka Moment
At the 8th hour of programming I actually cheered “IT WORKS!” When fine-tuning a model… it isn’t always obvious if things are actually “working” or not. Especially early on. Its difficult to measure. And once the process begins working… it is unlike any other programming. We are not simply making sequential commands. We have these creative “ah’ha” moments that are impossible to simply describe in words. It truly is different.
It was time to program the integrations – some plain, old, vanilla, Von Neumann machine coding.
The core of the integration needed a process which pulled in emails via Acumatica’s API, extracted key data, and fed that to our freshly trained model. Then, the model’s output was the payload for a PUT API call which ultimately creates sales orders.
We were ready to test. Success!! … or so we thought. It’s like that feeling when you disassemble and rebuild your car’s engine and end with “spare parts” (I may be speaking from personal experience here).
We committed a classic machine learning sin, we tested on our training data. Rookie move.
Data Labeling: The Tedious but Crucial Step No One Talks About
Saturday morning at 11 am. We had 25 hours until presentations (minus the essentials: 8 hours sleep, shower, and you know, the important things)
We gathered at the venue, reviewed the architecture, and jumped right into prepping our training data. This is one of the least romantic things one can experience in building out a machine learning product… but it’s completely essential to success. This is when we took a hard look at the emails we were using to train the model. While Lakshmi inputted the actual training data, Kulvir and I wrangled a very difficult shape that would actually work within Acumatica for creation of Sales Orders. It was truly a joint operation of painstaking, precise work.
Six long, mind-numbing hours later, I was done with my JSON structuring! By the time dinner rolled around, we had our dataset, and a renewed enthusiasm! (Mostly).
It was time to program the integrations – some plain, old, vanilla, Von Neumann machine coding.
The core of the integration needed a process which pulled in emails via Acumatica’s API, extracted key data, and fed that to our freshly trained model. Then, the model’s output was the payload for a PUT API call which ultimately creates sales orders.
We were ready to test. Success!! … or so we thought. It’s like that feeling when you disassemble and rebuild your car’s engine and end with “spare parts” (I may be speaking from personal experience here).
We committed a classic machine learning sin, we tested on our training data. Rookie move.

Our model was only hitting a 50% success rate… And then… all the air seemed to leave the room. The marketing team stared at me as if I’d grown a second head.
Are you serious? You want us to sell a 50% error rate? Can you… like… try harder?
They were right, of course. We had a 50/50 chance of making the correct order? That is not the sort of gamble you give your customers.
Deeper Knowledge: Loss Functions
Loss functions measure the “cost” of our model being incorrect. If a model is highly inaccurate the loss value will be high. If the loss is low the model is considered very accurate (in most situations). Machine Learning algorithms are about minimizing the loss function so it can become better and better with data.
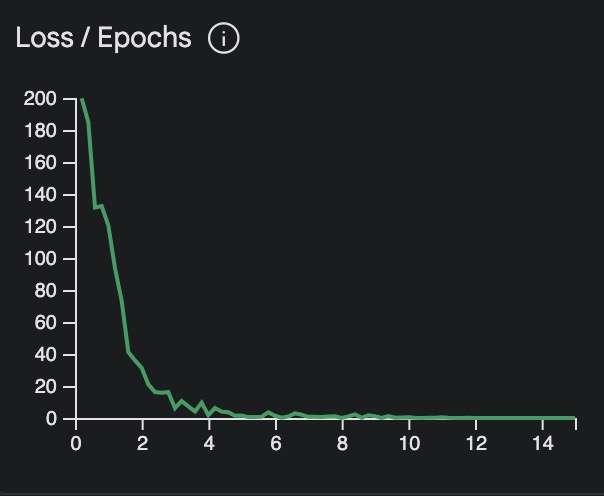
Technical Details:
- Base Model: Gemini 1.5 Flash 001 Tuning
- Tuned Examples: 20 (real emails) + 20 (synthetic)
- Epochs: 13
- Batch Size: 4
- Learning Rate: 0.001
Synthetic Data
Saturday 9pm. 15 hours till presentation (aka 7 hours of productive time).
It was time to pull some rabbits out of our hats. It’s important in AI to train on the proper data, but you can’t win a hackathon without some hacking. To address our 50% failure rate, we used our trusty LLM to generate 20 synthetic emails. We asked our model to duplicate the style of our current emails, and for “random emails” that may not be connected to a sale order. One email, for example, simply requested “a gallon of milk”.
Yes, data-labeling is back. But, for the last time! (probably) We tagged all new “synthetic” data with “GUEST” for unknown customers and “NOTFOUND” for unrecognized inventory items.
Synthetic Data Input
{ “Body”: { “value”: “Hi \r\nThe quick brown fox jumped over the lazy dog.\r\nas early as possible\r\n\r\n\r\n– \r\n\r\nOld McDonald” }, “From”: { “value”: “OldMcDonald@example.com” }, “Subject”: { “value”: “He had a farm” } }
Synthetic Data Output
{ “OrderType”: { “value”: “SO” }, “CustomerID”: { “value”: “GUEST” }, “Details”: [ { “Branch”: { “value”: “PRODWHOLE” }, “InventoryID”: { “value”: “NOTFOUND” }, “OrderQty”: { “value”: 1 }, “UOM”: { “value”: “BOX” } } ] }
By closing time, we had over 90% success rate! ? One of our teammates asked “why we would even consider manually data entry any more?” If this can be done in 20 hours of work, why would we ever go back?